How Git Works
So far this week we’ve talked about what Git is and how to use it. If you’re anything like me, you want to know how things work under the hood. When you first learn Git it can seem like magic…but it also seems like something that can easily break. Or something that works by pure demonic byte voodoo. One of the best things Git does is allow you to write code with confidence - fear not about breaking things or losing files. They’re always recoverable. To feel confident, it helps to know how things work.
This XKCD comic perfectly summarizes how most people
use Git.
 I hope by the end of this post you feel a little more confident.
I hope by the end of this post you feel a little more confident. ![]()
Git works differently than most other version control systems. As a result, it runs freakishly fast and has some killer features that elevate it above the competition. We’ll cover some basic VCS principles and look at some of the cogs that make the Git machine tick.
Understanding Diff
You have to know what a diff is to understand how version control systems work. A diff is essentially just a difference between two things. In the case of Git and many other version control systems, a diff is the difference between two files. Linux actually has a diff utility that can tell you the difference between two files. It works by examining each line individually. Here’s a quick example.
Let’s assume that file1 contains:
This is a file!
Hello world!
End of file.
and file2 contains:
This is a file!
Goodbye, world.
End of file.
If you run $ diff file1 file2 you will get a result that looks like:
2c2
< Hello world!
---
> Goodbye, world.
Here’s what that means:
- The first line,
2c2, gives us an overview of what happened.- The
cmeans that a line was changed. - The number before the
c, a2in this case, is the line in the first file that corresponds to the change. - The number after the
c, also a2, is the line in the second file that has changed.
- The
- The
<denotes the line(s) in the first file. - The
>denotes the line(s) in the second file. - the
---separates the contents from the first and second files.
If we were to delete line 2 in the second file, so that it’s contents just look like:
This is a file!
End of file.
the diff would look like this:
2d1
< Hello world!
- Again, the first line
2d1gives us a snapshot of the difference.- The
dmeans a line was deleted. - the
2means line number 2 in file1 was the edited (deleted) file. - The
1means that in file2, the change happened after line number 1. Or, after deletion, the line counter went back to line number 1.
- The
- The
< Hello world!is the line from file1 that was deleted. - Nothing was changed or added in
file2, so there are no---and>markings.
![]() The first part,
The first part, 2c2, 2d1, etc can often times be ignored - these are
mostly intended for use by the linux tool patch.
git-diff works a little bit differently than the diff tool and the output is
different, but the basic idea of a diff is the same. Here’s an example from
two different commits in this repository. We’re going to look at the difference
between commit d8ee32d55db5ba04456d7ac214e7f02d3151081c and commit
f7fababd22ea85dba012c69aebac0067769b1208. Here’s the output from git-log
so you can see what we’re working with.
$ git log
commit f7fababd22ea85dba012c69aebac0067769b1208
Author: Dakota Chambers <dakotachambers@gmail.com>
Date: Sat Apr 14 14:47:02 2018 -0500
Change grammar in 'Understanding Diff' section.
commit d8ee32d55db5ba04456d7ac214e7f02d3151081c
Author: Dakota Chambers <dakotachambers@gmail.com>
Date: Sat Apr 14 14:46:08 2018 -0500
Start writing how-git-works post.
To see what change I made between those commits, I can use $ git diff!
![]() when working with the uniquely identifying SHA-1 HASH of each commit, you
don’t have to use the whole thing. Often times the first 6 characters of each
HASH value is enough.
when working with the uniquely identifying SHA-1 HASH of each commit, you
don’t have to use the whole thing. Often times the first 6 characters of each
HASH value is enough.
$ git diff d8ee32 f7faba
diff --git a/_posts/2018-04-14-how-git-works.md b/_posts/2018-04-14-how-git-works.md
index 49076cc..633c386 100644
--- a/_posts/2018-04-14-how-git-works.md
+++ b/_posts/2018-04-14-how-git-works.md
@@ -14,7 +14,7 @@ files. Linux actually has a *diff* utility that can tell you the difference
between two files. It works by examining each *line* individually. Here's a
quick example.
-Let's assume file1 contains:
+Let's assume that file1 contains:
` ` `
This is a file!
Hello world!
Normally, your git-diff will be color coded for easier reading. It will look
something like this:
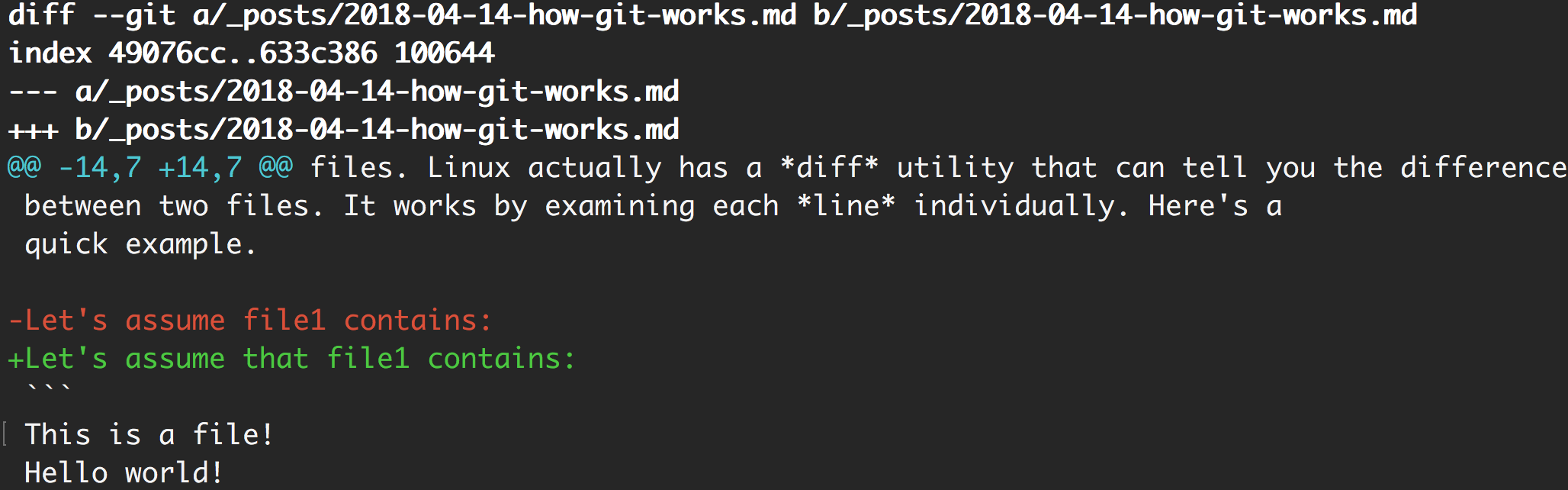
Whoa, this looks a lot scarier! Let’s break it down…there’s only a few things we care about for this example. The first part
--- a/_posts/2018-04-14-how-git-works.md
+++ b/_posts/2018-04-14-how-git-works.md
is basically a unified diff header. Essentially, the --- is the old file and
the +++ is the new file. The next part
@@ -14,7 +14,7 @@
gives us information about what lines were changes and what the diff is showing. You can ignore the @ signs, those are just markers.
-
-14,7is short hand for representing the changes in the first file. In the file, the diff starts on line 14, and it is 7 lines long. The actual diff isn’t 7 lines long, but it’s showing 7 lines from the file. -
+14,7is short hand that represents the changes to the second file. Again, the diff is showing a “chunk” that starts on line 14 and is 7 lines long.
The most important part what comes after that section. It is showing the contents
of both files. Anything without a - or + in front of it is the same in both
files, while any line with those markers present is a line that was changed.
The - is a line that was removed from the first file, and the + is a line that
was added in the second file.
-Let's assume file1 contains:
+Let's assume that file1 contains:
Because diff works on a line-by-line basis, it views these two lines as totally
different even though I only added a single word. So this is saying that I deleted
a line containing Let's assume file1 contains: and aded a line that contains
Let's assume that file1 contains:. The words below the -/+ section are just
some more contents of the file to help give context.
And that’s how diff works! The first step in understanding Git/version control
is to know that they operate by tracking changes in files.
Snapshots, not Differences
If you look at the the official documentation, you’ll see that Git doesn’t actually work by tracking diffs. Instead, Git keeps a snapshot of the current state of a directory. Haha, you’ve been fooled! You learned the magic of diff for nothing! Fret not - it’s still important to know what a diff is to understand why Git is different. Git still uses diffs to know when a file has been changed. Some version control systems, like CVS, Subversion, Bazaar, etc work by tracking diffs. This is called delta-based version control.
Git works a little differently. Every time you make a commit, Git takes a snapshot of all the files, and then creates a reference to those files in there exact form at that moment in time. If you change a file and make another commit, Git takes another snapshot and creates another reference. At a glance this seems horribly inefficient - you would think that your repo would rapidly increase in size with every commit you make if it keeps a copy of every file in every commit, right? Luckily, Git is smart about taking snapshots! If a file hasn’t changed from a previous version when you make a commit, it doesn’t actually save another copy of that file. Instead, it just saves a link to the previous (identical) version of that file. You can imagine it similar to how a symlink works in a Unix-like operating system.
This distinction actually allows Git to do a lot of the cool things that other version control systems cannot. For example, Git has an incredibly powerful branching model due to the nature of how it works that many other VCS can not compete with.
All right. Diffs, snapshots…apples, oranges, you get it. Moving on!
Three States
Files in a Git repository have three states they can be in: modified, staged, and committed.
- When you make a change to a file and save that change, it is marked as modified. At this stage, Git has not recorded the changes. If you were to delete the file, you would not be able to recover it with those changes present.
- Once your have edited your file and area ready to commit it, you need to use
git addto stage the file. This marks the file as staged. It updates the snapshot (index) to the contents of the file in the current working directory. Staging a file tells Git you are ready to add it to the next commit. - Finally, you can use
git committo mark a file as committed. In this stage, the file is backed up in the Git ‘database’. At this point, it’s virtually impossible to accidentally make a file non-recoverable. This image from the Git Documentation describes the stages pretty well: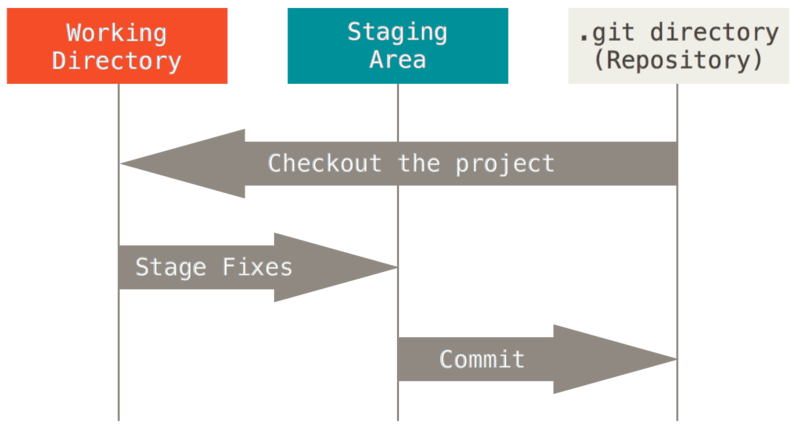
The .git directory
When you create a new Git repo with git init or git clone an existing repo,
you’ll notice that Git creates a .git directory within your repo. The .git
directory contains all the goodies that make Git work. Try using tree to
inspect the contents of that directory.
$ tree .git -L 2
.git
├── COMMIT_EDITMSG
├── FETCH_HEAD
├── HEAD
├── ORIG_HEAD
├── branches
├── config
├── description
├── hooks
│ ├── applypatch-msg.sample
│ ├── commit-msg.sample
│ ├── post-update.sample
│ ├── pre-applypatch.sample
│ ├── pre-commit.sample
│ ├── pre-push.sample
│ ├── pre-rebase.sample
│ ├── prepare-commit-msg.sample
│ └── update.sample
├── index
├── info
│ └── exclude
├── logs
│ ├── HEAD
│ └── refs
├── objects
│ ├── 00
│ ├── info
│ └── pack
├── packed-refs
└── refs
├── heads
├── remotes
└── tags
Let’s break down what we see here.
-
COMMIT_EDITMSGis simply the message from your last commit. -
FETCH_HEADis the SHA-1 Hash of the remote/branch that was updated the last time you rangit fetchorgit pull. -
HEADis the current ref (commit reference) you’re looking at. -
ORIG_HEADis the SHA-1 Hash of the branch you are merging into when doinggit merge -
MERGE_HEAD(not listed above) is the SHA-1 Hash of a branch you’re merging from withgit merge. (e.g. this is the branch that gets merged into the branch that the ORIG_HEAD SHA-1 Hash points to). -
branchesis a directory that is ‘A slightly deprecated way to store shorthands to be used to specify a URL to git fetch, git pull and git push.’ according to the official documentation. You can consider this deprecated - you won’t have to worry about it. -
configcontains repository settings. -
descriptionis used only by the GitWeb program - you can safely ignore it. -
hooksis a directory that contains scripts that can run automatically when you do certain git actions (e.g. push to a branch). Hooks are an incredibly powerful way to interact with Git. There are many tools that you can tie into Git using hooks to automate certain actions. For example, you can use a hook with Jenkins to automate a build and deployment after commiting to a certain branch. For more information about hooks, check out the documentation. -
indexis a file that contains all kind of information about the current snapshot of the repository. -
infois a directory that contains some additional information about the repo.-
excludeis a file that contains an exclude pattern list. Many people will find using the regular.gitignoreis fine.
-
-
logsis a directory that contains a log from various branches.-
HEADshows the log of the HEAD ref. -
refsis a directory that contains logs of other refs.
-
-
objectsis a directory that contains blobs of data that Git stores. This directory will grow over time. -
packed-refscontains the same information as therefsdirectory in a more efficient way. -
refsis a directory that contains all of the references of the repository.
The core parts of Git are the HEAD, index, objects directory, and refs
directory. Git uses a bunch of low-level commands to manipulate data within
these files/directories.
Plumbing vs. Porcelain
Git was originally created as a toolkit for other version control systems, not
as a stand-alone version control system. As a result, there are a number of
low-level “plumbing” commands that are designed to be strung together and
executed by scripts. The user-facing commands, such as checkout or commit
are sometimes referred to as “porcelain” commands. When working directly with
Git from the command line, you’ll rarely ever have to use the “plumbing”
commands. In fact, most of the “porcelain” commands you are familiar with
actually use a bunch of “plumbing” commands.
I’m not going to dig too far into the Git plumbing commands - that’s enough material for a whole book. If you want to learn more, check out the documentation.
Objects and References
Objects and References (Refs) are the core of what makes git work.
Objects
Git is a content-addressable filesystem, or simply put, Git uses a key-value data store. This is a concept most programmers learn early into their education. A key-value data store means that you can add any type of file to a Git repository, and Git will generate a unique key for that object. Key-value data stores have become somewhat popular lately due to their speed and scalability. Some common database examples are Redis and DynamoDB.
We’ve already learned that Git uses Hash functions to refer to specific commits
and branches. Git uses Hashes to refer to objects as well. For example, the
plumbing command git hash-object takes some file, stores the data in the
.git/objects directory, and returns the hash value that it stored the data at.
Commits are stored as Objects too! Ever wonder why Git is so damned fast? It’s largely due to the key-value data model it uses.
Trees and Blobs
All objects that Git stores are either a blob or a tree. A blob is just a fancy way of referring to a binary file. A tree object is used to store filenames and groups of files. A single tree object can contain other tree objects, and SHA-1 Hash values that point to a blob of data or other subtrees. Basically, Git stores data similar to a regular Unix-like filesystem.
References
References (Refs) are the yin to the Git Object’s yang. While everything is stored
in Git as a blob referenced by SHA-1 Hashes, References allow you to refer to
that data without having to use hash values. HEAD for example, is a reference
that points to the SHA-1 Hash’d commit object of the most recent commit.
A branch is a reference to a certain commit, and all of the history that commit includes.
Tags
A tag is a handy way of referring to a specific commit. It’s kind of like a branch reference, except it does not ‘move’ as you make more commits in that branch. Tags are useful for doing release-management with Git.
Remotes
A remote is a reference that points to a remote git server. For example, when
you clone a repo from Github it creates a remote named origin. Once you’ve
added a remote and pushed to it with git push, Git stores the value you last
pushed in the .git/refs/remotes directory. You can always reference this
directory to see what a branch looked like the last time you pushed it to the
remote server. A remote is different than a branch in that Git considers it
“read only.” This is why your commits don’t write directly to the remote repo.
The HEAD never points to a remote, but to a local branch/commit.
Putting It All Together
Okay, we’ve look at some of the things that make Git work behind the scenes. Let’s take a minute to re-cap and put all the pieces together.
- Typical version control systems work by tracking changes to files. Git, however, is not a delta-based VCS. Git takes a snapshot of the directory when you make a commit.
- Every file in a Git Repository can be in one of three states:
- Modified
- Staged
- committed
- Every Git repository has a .git directory that contains pretty much everything needed for Git to work.
- Git has two types of commands, plumbing and porcelain.
- Porcelain commands are what a user types into a terminal to perform regular Git operations.
- Plumbing commands are low-level commands used by Git and other scripts to actually manipulate data, objects, and references.
- Objects and References make the world go ’round.
- Everything in Git is stored as an object in a key-value data store.
- Git uses an SHA-1 hashing algorithm to store data as blobs.
- References are nice ways to refer to SHA-1 hashes so we don’t have to memorize and type 40-digit hexadecimal hash values.
- Everything in Git is stored as an object in a key-value data store.
And that’s the basics of how Git works!
Thanks for reading! This post (and Git 101) ended up
taking a lot more time writing than I originally anticipated. As a result, I’m
pushing back the upcoming “Git vs. the Competition” post to early next week to
wrap up “Git Week 2018.” For those of you that are getting tired of Git - new
content is coming too! Thanks for sticking it out this far. ![]()
Comments